728x90
반응형

InnoDB storage architecture
- storage engine 중 거의 유일한 record기반 lock 지원
- 동시성, 안정성 높음
cluster by primary key
- 기본적으로 primary key 기준 clustering
- key 순서로 disk에 저장
- secondary index는 record를 참조하지 않음, primary key를 참조
- primary key를 이용한 range scan 성능 향상, primary 비중이 높음(실행계획도 primary 기준으로)
- MyIsam에선 clustering key 지원 안함
- key 순서로 disk에 저장
foreigner key
- InnoDB storage engine level에서 지원 / MyIsam, memory engine에선 지원 안함
- 부모, 자식 DB 칼럼에 index 설정
- 변경시 체크작업으로 인해 lock 전파주의
- foreign_key_checks시스템 변수 off시 체크작업 안함(긴급할때만, 평소 on)
- off -> on 시 정합성 맞춘 후 해야함
MVCC(multi version concurrency control)
- record level transection을 지원하는 DBMS가 지원
- lock을 사용하지 않는 일관적 읽기 지원
- undo log를 사용하여 구현(innoDB)
- innoDB는 ACID(atomicity, consistency, isolation, durability)을 보장
- update를 치면 commit전에도 disk와 버퍼풀의 데이터가 평소(대략적)에 같음
- 기본적인 흐름은 undo log에 기존 내용 저장 -> 버퍼풀에 바뀔 데이터로 갱신
- commit전 조회하면 transection-isolation의 level에 따라 내용이 다르게 조회됨
- read_uncommited -> 버퍼풀의 값 반환
- repeatable, serializable -> undo log의 값 반환
- transection이 길어지면 undo log에 예전 데이터를 삭제하지 못하여 table space 공간이 많아짐
- commit시 변경작업 없이 영구 data로 바뀜(undo_log 삭제)
- undo_log는 바로삭제 되지 않음, 해당영역을 참조하는 transection이 없을때 삭제됨)
- rollback시 undo_log data -> bufferpool -> undo_log 삭제
(buffer pool의 데이터는 disk와 동기화 되는가?..)
Non-Locking Consistent Read (잠금없이 일관적으로 읽기)
- MVCC 덕에 transection이 걸려있어도 읽기 가능
- 격리수준(read_uncommitted, read_committed, repeatable_read, serializable)이 serializable이 아니면 insert와 관련없는 읽기는 transection에 구애받지 않고 바로 실행 가능하다.
자동 dead-lock 감지
- 교착에 빠졌는지 확인하기 위해 잠금 대기목록을 wait-for-list 그래프로 관리
- dead-lock 감지 thread가 있어 주기적으로 그래프를 검사, 교착 transection이 있다면 이 중 undo_log 양이 적은 하나를 강제종료 한다.
- undo_log 양이 적은게 rollback시 부하가 적다.
- 잠금목록 검사를 위해 잠금리스트에 잠금을 걸고 현 상태를 snap-shot찍은 상태에서 검사한다
- 동시처리나 트렌젝션 잠금이 많아지면 해당 thread는 느려진다.
- 해당 thread가 느려지면 서비스 쿼리는 대기하며 이 또한 느려지는 악영향을 미친다.
- 이때를 위해 innodb_deadlock_detect 시스템 변수를 제공하며 off시 감지를 하지 않는다.
- off시, storage engine 내부에서 2개이상 transection이 상대방이 가진 lock 자원을 요청해도 중재하지 않아 deadlock 상태에 빠질 확률이 있다.
- 이때를 위해 innodb_lock_wait_timeout를 활성화 하면 위 상황에서 자동요청 실패가 되며 에러 메세지를 반환한다. (기본값 50초 보다 낮게 설정)
- innodb_deadlock_detect off시 innodb_lock_wait_timeout를 무조건 같이 설정해야하며, 케이스에 따라 성능향상이 될 수 있다.
- 해당 thread가 느려지면 서비스 쿼리는 대기하며 이 또한 느려지는 악영향을 미친다.
자동화된 장애 복구
- Mysql 서버가 시작될때 완료하지 못한 transection이나, disk 일부에만 기록된 데이터 페이지 등에 대한 복구가 자동으로 진행된다
- innoDB 자체문제일 확률은 극히 낮으며, disk나 하드웨어의 이슈로 자동복구 되지 못하는 상황이 대부분이다
- 자동 복구가 진행되지 않으면 Mysql 서버 종료 후 innodb_force_recovery 시스템 변수를 설정하여 실행하여 수동 복구를 진행한다.
- 데이터 관련 = 1, 로그 = 6 (값이 클수록 복구가능성이 낮으며 심각한 수준)
- 서버가 위 명령으롤 켜진진다면(select밖에 안됨) mysqldump를 사용하여 백업, 서버의 db와 table를 재생성하는 것을 추천한다.
- 서버 시작시 undo_log를 data에 덮어 씌우고, redo_log를 덮어씌워 장애시점 데이터 생성
- 이때 정상 mysql은 최종적으로 commit되지 않은 transection rollback
- 풀백업~장애시점의 binary log가 있다면 innoDB 복구보단, 풀백업과 binary log로 복구하는게 손실이 적다
- binary log가 없다면, 마지막 풀백업까지만 복구 가능
버퍼풀(innoDB)
- disk의 datafile, index 정보를 memory에 cache 해 두는 공간
- 쓰기 작업을 지연시캬 일괄 처리하여 버퍼 역할도 함 (disk 접근을 낮춰 성능 향상)
크기
- 기본적으로 80%라 되어있는데 이렇게 설정하면 안됨. OS와 client가 사용할 memory 고려
- Mysql 서버내 메모리 필요부분은 크게 없음, 독특한 케이스로 record buffer가 상당한 memory 사용하기도 함
- record buffer: 테이블의 record r/w시 buffer로 사용하는 공간. connection과 table이 많으면 공간이 많이 필요
- Mysql 서버의 record buffer 공간은 별도의 설정이 불가하며 전체 connection, connection의 r/w 테이블 개수에 따라 결정지만, 동적 해재도 되어 정확한 메모리 공간 크기를 계산할 수 없음
- Mysql 5.7 부터 innoDB의 버퍼풀 크기를 동적으로 조절 가능 (innodb_buffer_pool_size )
- 적은값부터 설정하여 상황에 맞게 조금씩 증가하며 최적값을 찾아 나아가야함
- Mysql 서버를 이미 사용하고 있다면, 해당 서버의 메모리 설정 기준에 맞춰 설정해야함
- 신규 구축시 8GB 미만: 50%정도 innoDB 버퍼풀로, 나머지는 Mysql서버, OS, 다른 시스템이 사용할 수 있도록 남겨두는것을 권장
- 신규 구축시 8GB 이상: 50%부터 점차 증가시켜 최적값을 찾아야함
- 신규 구축시 50GB 이상: 15~30GB 남기고 버퍼풀로 할당
- 적은값부터 설정하여 상황에 맞게 조금씩 증가하며 최적값을 찾아 나아가야함
- 버퍼풀 공간을 줄이는건 크리티컬한 작업이므로 서버가 한가할때 해야함(늘리는건 영향 없음)
- 128MB 단위로 처리되어 해당 청크 단위로 줄이거나 늘려야함
- 버퍼풀을 전체 관리하는 세마포어로 인해 내부 잠금경합을 유발하며, 이를 줄이기 위해 버퍼풀을 쪼개어 관리할 수 있게 개선되었다(분산 경합)
- innodb_buffer_pool_instances 로 관리
- 각 버퍼풀은 버퍼플 인스턴스이며 기본적으로 8개이다.
- 단) 메모리 1GB 미만: 1개, 40GB 이하: 8개, 그 이상: 5GB당 1개 설정하는게 좋다.
버퍼풀 구조
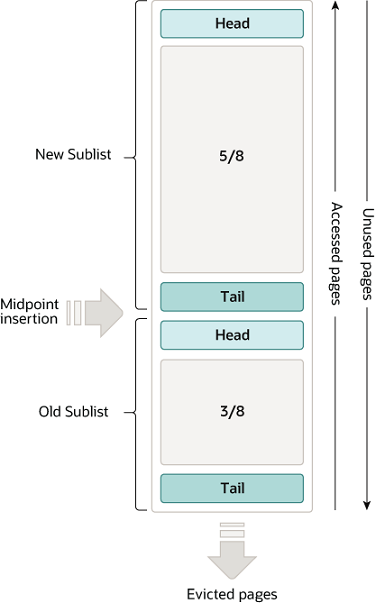
- 버퍼풀이라는 메모리 공간을 page크기(innodb_page_size)의 조각으로 쪼개어 storage engine이 데이터를 필요로 할때 해당 page를 읽어 각 페이지에 저장
- 버퍼풀의 페이지 크기조각을 관리하기 위해 free list, LRU list, flush list 라는 3개 자료구조를 관리
- freelist: 버퍼풀에서 실제 사용자 data로 체워지지 않은 비어있는 page 목록
- 사용자 query가 새롭게 disk data page를 읽어와야 할때 사용/
- LRU list: LRU와 MRU list가 결합된 형태
- old sublist: LRU, new sublist: MRU이며 새로운 page는 이 경계에 들어간다.
- disk로 부터 한번 읽은 page는 오래동안 버퍼풀 memory에 유지하여 disk i/o를 줄이기 위함
- flush list: 더티페이지(디스크로 동기화 되지 않은 데이터를 가진 페이지)의 변경 시점 기준의 페이지 목록 관리
- 읽은 상태 그대로 변경이 없다면 flush list는 관리하지 않으며, 변경이 있어야 관리하고
특점 시점에 disk로 기록해야한다. - 데이터가 변경이 되면 redo-log에 기록, 버퍼풀 데이터 페이지에도 반영한다.
- redo-log의 각 entry는 특정 data page와 경결이 된다.
- 하지만) redo-log가 disk로 기록한다는 것은 데이터 페이지가 디스크에 기록된다는것과 다르다.
- 이를 위해 체크포인트를 발생하여 이를 동기화한다.(어느 부분부터 복구해야할지 판단 기준이 되기도 한다)
- 읽은 상태 그대로 변경이 없다면 flush list는 관리하지 않으며, 변경이 있어야 관리하고
- freelist: 버퍼풀에서 실제 사용자 data로 체워지지 않은 비어있는 page 목록
Buffer pool 과 redo log
- flush list에서 언급한것 처럼 redo log와 버퍼풀은 밀접한 관계를 가진다
- 버퍼풀은 서버 메모리가 허용하는 만큼 크게 설정할 수록 쿼리성능이 좋아진다
- 버퍼풀은 db서버 성능을 위해 데이터 캐시, 쓰기 버퍼링 두 가지 용도가 있다.
- 버퍼풀의 메모리 공간만 늘리는 것은 데이터 캐시의 기능만 향상 시킨다.
- 쓰기까지 향상하려면 redo log <-> 버퍼풀의 관계를 이해할 필요가 있다.
- 버퍼풀은 clean page(읽고 변경이 일어나지 않은 page), dirty page(읽고, 쓰고, 지우는 명령으로 변경된 데이터를 가진)가 있다.
- InnoDB storage engine에서 redo log는 1개 이상 고정 크기파일을 연결하여 순환고리처럼 사용한다.
- 변경이 계속 발생하면 redo log 파일에 기록되었던 log entry는 다시 새로운 log entry에 의해 덮여쓰여진다.
- 이때 로그 포지션은 증가한다.(LSN: log sequence number)
- 이때문에 redo log 파일에서 재사용/재사용불가(active redo log) 공간을 분리하여 관리한다.
- 변경이 계속 발생하면 redo log 파일에 기록되었던 log entry는 다시 새로운 log entry에 의해 덮여쓰여진다.
- innoDB storage engine은 주기적으로 체크포인트 이벤트를 발생시켜 redo log와 버퍼풀의 dirty page를 동기화 시킨다.
- 가장 최근 체크포인트 지점의 LSN이 활성 redo log 공간의 시작점
- 가장 최근 체크포인트 지점과 마지막 redo log entry LSN차이 = check point age = active redo log 공간 크기
- 정리1) 버퍼풀의 dirty page는 특정 redo log entry와 관계가 있다.
- 정리2) InnoDB는 주기적으로 체크포인트를 발생시키고 이보다 작은 LSN을 가진 redo log entry와 관련된 dirty page는 이 둘 모두 disk로 동기화 되어있어야 함
버퍼 풀 플러시 (disk 동기화)
- 기존에는 dirty page flush를 하면 page가 많으면 disk I/O가 늘어난다. 그래서 사용자 쿼리 처리에도 영향을 미첬다.
- Mysql 8.0 부터 flush list flush, LRU list flush 두 가지 flush기능을 background에서 실행시키며 disk I/O 폭증 현상을 잡았다.
플러시 리스트 플러시
- redo log 공간을 재활용하기 위해 주기적으로 오래된 log entry를 비워야 함
- 주기적으로 flush list 플러시 함수를 호출하여 오래전 변경된 데이터 페이지 순서대로 디스크에 동기화
- 언제부터 얼마나 많은 더티페이지를 한번에 디스크로 기록하는지 시스템 변수로 설정할 수 있음.
- innodb_buffer_pool_instances와 innodb_page_cleaners 개수를 똑같이 맞추는게 좋음
- 클리너 스레드: InnoDB storage engine에서 dirty page를 disk로 동기화 하는 스레드
- 기본적으로 전체 버퍼풀이 가진 페이지의 90%까지 더디페이지를 가질 수 있다.(innodb_max_dirty_pages_pct 로 조정 가능)
- 더티 페이지를 많이 가질 수록 disk 쓰기를 줄일 수 있다.
- 너무 많이 가지고 있으면 Disk IO Burst 현상이 발생할 수 있어 일정 수준 이상 더디페이지를 가지게 되면 조금씩 (default: 10%) disk로 기록한다.
- 어뎁티브 플러시: 리두 로그가 증가하는 속도를 기반으로 적절한 수준의 더디 페이지가 버퍼풀에 유지 될 수 있도록 디스크 쓰기를 한다(dafult)
LRU 리스트 플러시
- 사용빈도가 낮은 데이터 페이지를 제거하여 새로운 페이지를 읽어올 공간을 만드는 것.
- LRU리스트 끝부분부터 시작하여 설정된 개수만큼 스캔하여 디스크에 동기화하며, 클린페이지는 바로 프리 리스트로 옮겨진다.
버퍼 풀 상태 백업 및 복구
- 버퍼풀은 쿼리 성능에 매울 밀접하게 연결되어 있다. 버퍼풀 캐싱이 안되어있다면 성능이 1/10도 안된다.
- 버퍼풀에 체워주기 위해 기존엔 사용자가 주요 테이블 full scan 하는 방식으로 warming up 했다.
- 이제 개선되어 버퍼풀 상태를 백업 할 수 있다.(innodb_buffer_pool_load_now=ON)
- 버퍼풀의 LRU 리스트에서 적재된 데이터 페이지의 메타정보만 가져와 저장한다. (저장은 빠름, 복구는 느린 이유)
- 서버가 시작되면 자동 복구를 위해 innodb_buffer_pool_dump_at_shutdown, innodb_buffer_pool_load_at_startup 설정을 Mysql 서버의 설정파일에 넣어준다.
버퍼풀 적재 내용 확인
- information_schema 데이터베이스에 inndb_cached_indexes 테이블을 확인하면 된다.
- 하지만 아직 Mysql 서버는 개별 인덱스별로 전체 페이지 개수가 몇 개인지는 사용자에게 알려주지 않는다.
728x90
반응형
'책 > RealMySQL' 카테고리의 다른 글
| RealMySQL 5.1 - 트랜잭션 (0) | 2023.04.04 |
|---|---|
| RealMySQL 4.4 - MySQL 로그 파일(log file) (0) | 2023.03.18 |
| RealMySQL 4.3 - MyISAM 스토리지 엔진 아키텍처 (0) | 2023.03.18 |
| RealMySQL 4.2 - InnoDB 스토리지 엔진 아키텍쳐 (2) (0) | 2023.02.19 |
| RealMySQL 4장 - 4.1 MySQL 엔진 아키텍처 (0) | 2023.01.20 |



