
B Tree (B 트리)
- 가장 널리 사용되는 인덱스 구조 ( RDB / NoSQL)
- SS 테이블과 동일하게 K-V 정렬 유지 (키 - 값 검색 / 범위 쿼리 효율적)
기본 구조
- 4KB 내외 크기의 고정 크기 페이지(블록)로 나누고 한 번에 하나의 페이지에 읽기 또는 쓰기 (디스크는 고정 크기 블록으로 배열되기 때문)
- 각 페이지는 주소나 위치를 이용해 식별 가능 -> 해당 방식으로 하나의 페이지가 다른 페이지를 참조 가능
- B tree 구조에는 하나의 루트 페이지 존재 (색인에서 키를 찾기 위해서는 루트에서부터 시작)
- 페이지는 여러 키와 하위 페이지 참조를 포함
- 최종적으로는 리프 페이지를 포함하는 페이지에 도달
- 분기 계수 : 한 페이지에서 하위 페이지를 참조하는 수 (페이지 참조와 범위 경계를 저장할 공간의 양에 의존적)

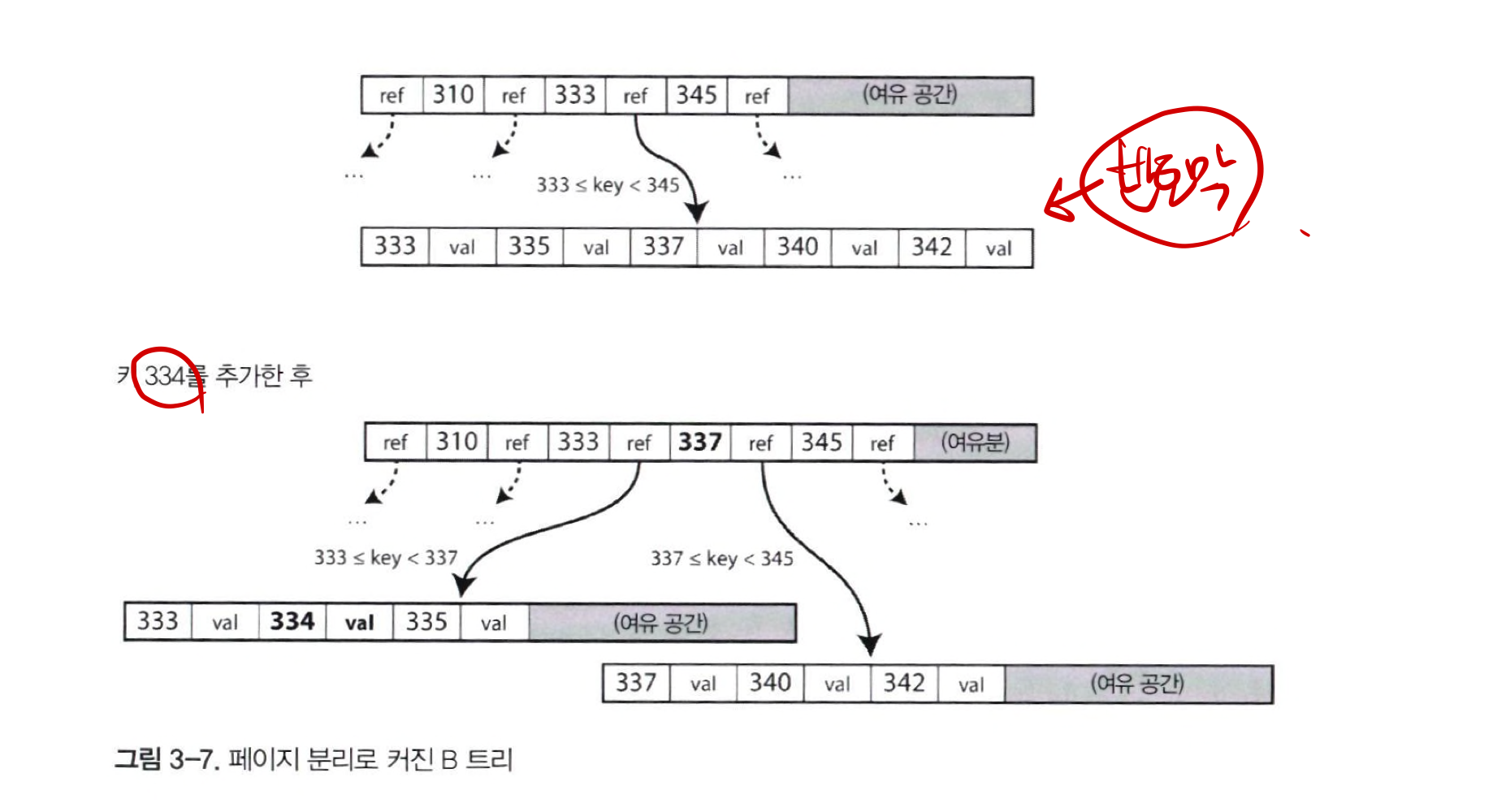
- 키 값 추가
- 새로운 키를 포함하는 범위의 페이지 찾기
- 해당 페이지에 키와 값을 추가
- 이 때, 새로운 키를 수용할 공간이 없을 때 페이지 하나의 내용을 두 개의 페이지로 분할 후,
부모 페이지가 새로운 키 범위의 하위 부분들을 알 수 있도록 갱신
- 키 값 갱신 :
- 키를 포함하는 리프 페이지 검색
- 페이지 값을 변경
- 페이지를 디스크에 다시 기록(페이지에 대한 모든 참조는 계속 유효함)
이를 통해 트리가 계속 균형을 유지하는 것 보장
n 개의 키를 가진 B 트리 -> 깊이 : O(log n)
신뢰할 수 있는 B 트리 만들기
B tree 쓰기 동작 : 새로운 데이터를 디스크 상의 페이지에 덮어씀
- 페이지를 덮어쓰더라도 페이지를 가리키는 모든 참조는 온전하게 남음 (LSM 트리와 같은 로그 구조화 색인과는 대조적)
- 로그 구조화 색인은 파일에 추가만 할 뿐, 같은 위치의 파일은 변경하지 않음
- 일부 상황은 여러 페이지의 덮어쓰기가 필요할 경우가 있다.
- ex) 삽입 때문에 페이지가 많아져 페이지를 나누어야 한다면,
분할된 두 페이지를 기록하고 두 하위 페이지의 참조를 갱신하게끔 상위 페이지를 덮어쓰기 해야함 - 일부 페이지만 기록하고 DB 장애시, 결국 색인이 훼손되기 때문에 고아 페이지(Orphan Page)가 발생할 수 있음
- ex) 삽입 때문에 페이지가 많아져 페이지를 나누어야 한다면,
DB 고장 상황에서 스스로 복수할 수 있도록 하는 방법
- 일반적으로 디스크 상에 write-ahead log (WAL - 재실행(redo) 로그)라고 하는 데이터 구조를 추가해 B 트리 구현
- WAL 로그 : 트리 페이지에 변경된 내용을 적용하기 전 모든 B 트리 변경 사항 기록 파일
DB 장애 이후 복구 전까지 일관성 있는 상태로 B 트리 복원에 사용
- 같은 페이지를 갱신하는 동시성 처리
- 다중 스레드가 B 트리에 접근 시, 동시성 제어가 필요함
- 동시성 제어는 래치[latch] (가벼운 잠금)로 트리의 데이터 구조를 보호한다.
- 대조적으로 로그 구조화 접근 방식의 동시성 제어는
유입 질의의 간섭 없이 백그라운드에서 모든 병합 수행,
atomic 적으로 새로운 세그먼트를 이전 세그먼트로 바꾸기 때문에 간단하다.
B 트리 최적화 방법
1. 페이지 덮어쓰기 / WAL 유지를 대신하여 copy-on-write schema(쓰기 시 복사 방식) 사용
-> 변경된 페이지 다른 위치 기록 + 트리에 새로운 버전의 상위 페이지 생성
2. 페이지의 키를 축약하여 공간 절약
-> 페이지 하나에 더 높은 분기 계수
3. 리프 페이지를 디스크 상에 연속된 순서로 트리에 배치
-> 쿼리가 키 범위의 상당 부분 스캔시 효율적
4. 트리에 포인터 추가
-> 상위 / 하위 포인터 자유롭게 key 스캔 가능
5. 프랙탈 트리(Fractal tree)
-> 디스크 찾기를 줄인다.
B 트리 vs LSM 트리
- 일반적 : LSM 트리 - 쓰기 빠름 / B 트리 - 읽기 빠름
- 읽기가 LSM 이 느린 이유 : 각 컴팩션 단계에 있는 여러 데이터 구조와 SS 테이블 확인
LSM 트리의 장점 ( B 트리의 단점 )
1. 색인에서의 쓰기 처리량
쓰기 증폭(write amplification) : DB에서 write 1번이 디스크에 여러 번 쓰기를 야기하는 효과
- B 트리 : 색인에서 모든 데이터 조각을 최소 두번 기록 (WAL + 트리 페이지(페이지 분리 시 또))
- 해당 페이지 내 몇 바이트만 바뀌어도 전체 페이지 기록해야하는 오버헤드
- LSM 트리 :
- 하지만 B 트리보다 쓰기 처리량을 높게 유지 가능
- 물론 색인에서 SS 테이블의 컴팩션 + 머지로 인해 여러 쓰기 작업 but 쓰기 증폭도 낮고, 컴팩션된 SS 테이블을 사용
2. 압축률
- B 트리보다 LSM 트리가 디스크에 더 적은 파일 생성 ( B tree - 파편화 문제 )
- LSM 트리는 페이지 지향적이기 때문에 파편화를 없애기 위해 SS 테이블 기록 -> 저장소 오버헤드 낮음
LSM 트리의 단점 ( B 트리의 장점 )
1. 컴팩션 과정이 때로는 읽기 / 쓰기 작업에 대해 성능에 영향을 미친다.
- 동시성의 영향이 없기 위해 요청을 대기할 경우도 있음
- 반면 B 트리의 성능은 LSM 엔진보다 예측하기 쉽다.
2. 디스크 쓰기 대역폭의 한계
- 컴팩션 문제 : 높은 쓰기 처리량 발생
-> logging & flushing 으로 백그라운드에서 수행되는 컴팩션 스레드가 대역폭 공유 - DB가 커질수록 컴팩션을 위해 더 많은 디스크 대역폭을 요구함
- 따라서 컴팩션에 대해서 모니터링이 필요함
3. B 트리는 각 키가 색인의 한 곳에만 존재한다.
- LSM 의 경우 다른 세그먼트에 같은 키의 다중 복사본이 존재할 수 있다.
- 따라서 B 트리는 강력한 트랜잭션 시맨틱(semantic)을 제공한다
기타 색인 구조
# 기본키(primary-key) 색인 : 가장 대표적인 K-V 색인 : R-model
# 보조 색인 (secondary index) :
- 보통 효율적으로 조인을 수행하는 데 결정적인 역할
- 기본키 색인과의 차이점 : 키가 고유하지 않다. (같은 키를 가진 많은 row / document / vertex 존재 가능 )
- B 트리 / 로그 구조화 색인 둘다 사용 가능
- ex) RDB - CREATE INDEX
# heap file (힙파일)
- 색인이 가지고 있는 값 : 실제 row / reference (참조 값)
- 참조일 경우 로우가 저장된 곳을 Heap file 이라 한다.
- 특정 순서 없이 데이터를 저장한다.
- 이 때 추가 전용이거나 나중에 새로운 데이터로 덮어 쓰기 위해 삭제된 로우를 기록 가능
- heap file 을 통한 접근 방식 = 키를 변경하지 않고 값 갱신 시 효율적
- 이 때 새로운 value가 힙에서 더 많은 공간을 차지해야 한다면,
충분한 공간이 있는 곳으로 위치를 이동시키고, 모든 색인이 레코드의 새로운 Heap 위치를 명시하게끔 갱신
or 이전 heap 위치에 전방향 pointer를 통해 처리
- 이 때 새로운 value가 힙에서 더 많은 공간을 차지해야 한다면,
# Clustered Index (클러스터드 색인)
색인에서 heap file을 이동하는 것 : 읽기 성능에 대해서 비효율적
- 따라서 색인 내에 바로 색인된 로우를 저장하는 방법 [Clustered Index]
- ex) Mysql - InnoDB 엔진 :
- table의 PK = 클러스터드 색인 / 보조 색인 -> 기본키참조(not Heap file location)
- MS의 SQL Server에서는 테이블당 하나의 클러스터드 색인을 지정 가능.
클러스터드 색인과 non 클러스터드 색인에 대한 설명은 다음 링크를 참조하면 잘 설명되어 있다.
- https://asfirstalways.tistory.com/339
RDB 성능 이슈 3. INDEX의 원리와 종류
RDB 성능 이슈 #3. INDEX의 원리와 종류 #왜 index를 생성하는데 b-tree를 사용하는가? 데이터에 접근하는 시간복잡도가 O(1)인 hash table이 더 효율적일 것 같은데? SELECT 질의의 조건에는 등호(<>) 연산도
asfirstalways.tistory.com
# multi-column index
가장 일반적인 유형 : 결합 색인(concatenated Index)
- 하나의 칼럼에 다른 칼럼을 추가하는 방식으로 하나의 키에 여러 필드를 결합
- 이 때 필드 연결 순서는 색인 정의에 명시

CREATE UNIQUE INDEX EMPLOYEES_PK
ON EMPLOYEES (SUBSIDIARY_ID, EMPLOYEE_ID) // 연결 순서- ex) (성, 이름) 순으로 정리된 전화번호 - 순서가 정렬되어 있기 때문에 다음과 같은 상황에 색인 사용 유용
- 특정 성으로 된 연락처 찾기
- 특정 성, 이름 조합을 가진 모든 사람 찾기
- cf) 특정 이름을 가진 모든 사람을 찾을 때는 쓸모가 없다.
# 다차원 색인(Multi-dimensional indexes)
- 한 번에 여러 칼럼에 질의한다.
- 특히 지리 공간 데이터에서 중요하게 사용.
- R 트리 같은 공간 색인에 특화(specialized spatial index)된 알고리즘을 사용.
# 전문 검색(Full-text Search) & 퍼지 색인(fuzzy Index)
- 특정 단어에 대해 동의어(Synonym)도 함께 질의에 추가할 때
- 특정 편집거리(오탈자 - misspellings)에 대해서 허용하여 질의에 추가하여 검색
- elasticsearch (루씬 기반) / 검색 엔진에서 흔히 사용된다.
추가적으로 RDB 인덱스에 관해서 살펴보다 좋은 글을 발견하여 참조한다.
'책 > 데이터중심 애플리케이션 설계' 카테고리의 다른 글
| 데이터중심 애플리케이션 설계 - 6장 [파티셔닝] 리뷰 - 1 (0) | 2022.10.20 |
|---|---|
| 데이터중심 애플리케이션 설계 - 4장 [부호화와 발전] 리뷰 (1) | 2022.09.25 |
| 데이터중심 애플리케이션 설계 - 3장 [저장소와 검색] 리뷰 - 3 : 트랜잭션 처리 / 분석 (0) | 2022.09.13 |
| 데이터중심 애플리케이션 설계 - 3장 [저장소와 검색] 리뷰 - 1 (0) | 2022.09.05 |
| 데이터중심 애플리케이션 설계 - 2장 [데이터 모델과 질의 언어] (0) | 2022.08.27 |



