Elastic Stack 이란

: Elastic의 모든 유형의 Data를 저장하거나, 실시간 검색, 분석 및 시각화할 수 있는 오픈 소스 서비스
v5.0.0 이전 : ElasticSearch + Logstash + Kibana 로 이루어진 서비스 - 흔히 ELK Stack 으로 명칭
v5.0.0 이후 - Beats 를 시작으로 X-Pack과 Elastic Cloud 가 포함되어 Elastic Stack으로 불림
엘라스틱이 좋다 좋다 하지만, 정말 뭐가 좋고 내세우는 게 무엇이며, 내가 왜 써야 하는 지를 알아야 한다고 생각했습니다.
Elastic Stack의 장점
(Elastic Search 시스템과 구조상의 장점에서 많이 비롯된다)
- 유연성 & 호환성
- Elasticsearch,Logstash,Kibana는 각각의 역할을 담당하기 때문에, 용도별로 분리해 version Up 및 발전하는 솔루션 - 구조적 안정성까지 보장
- 스키마가 자유롭다
- 수평 확장성
- 클러스터에 노드를 추가함으로써, 수평적으로 확장이 용이하다
- 부하 분산 및 안전성 확보
- 운영 및 확장성이 용이
- 클러스터에 노드를 추가함으로써, 수평적으로 확장이 용이하다
- 사전에 준비된 다양한 부가기능
- Kibana 를 통한 UI 및 다양한 부가기능 제공 - 사전의 다른 작업 요구 X
- ES 버전 별 Bulk 방법 차이 완화
- Bulk = (RDBMS)의 Insert
- ES는 버전 별로 벌크 방법의 차이가 존재한다.
- 하지만 Logstash를 통하여 ES 핸들링으로 벌크 문제를 해결
Elastic Stack 의 구조


Elasic Stack 구성요소
1. ElasticSearch

"그러면 루씬을 쓰면 되는거 아니에요? 왜 엘라스틱 서치를 써요?"
물론 루씬은 검색과 색인이 필요한 강력한 API를 제공한다.
하지만 결국 루씬은 어플리케이션이 아닌 라이브러리 , 따라서 사용자는 원하는 부분과 기능은 다 직접 개발이 필요하다.
반면에, Elasticsearch는 설치와 사용이 용이할뿐더러, 기반이 루씬이므로 루씬의 기능을 모두 제공한다.
또한 분산 처리를 비롯하여 다양한 기능들을 제공하고 대용량 데이터를 처리하기에도 적합하다(이유는 밑에서 설명)
ElasticSearch의 특징
- SchemaLess
- 전문검색(Full text Search) with 역색인 구조
- NRT(Near Real Time)
- RestFul API
- 클러스터식 구성
1. SchemaLess
여기서 스키마리스는 스키마가 없다는 뜻이 아닌, 동적으로 스키마가 생성된다는 의미이다.
기존의 RDBMS는 데이터를 입력하기에 앞서서, 테이블을 생성과 칼럼 정의 등 작업이 필요하다.
하지만 ElasticSearch는 데이터를 input하기에 앞서서 데이터의 어떤 필드를 저장할 것인지 사전에 정의가 필요하지 않다.
왜냐하면 elasticsearch는 자동으로 해당 데이터를 분석한 후에, 동적으로 스키마를 생성한다.
2. 전문검색(Full text Search) - with Inverse Index Structure
역색인 구조를 통하여 찾고자 하는 데이터가 어느 도큐먼트에 있는지 빠르게 검색 가능
(기존의 RDBMS는 where / like - 해당 조건에 맞는 데이터를 일일이 확인)


- 불규칙한 구조의 텍스트라도 색인 생성을 통하여 검색
- 다양한 데이터 타입 제공 (numeric, date , geo , ip ...)
3. Near Real Time(NRT)
실시간으로 분석이 가능한 System
- 색인과 검색이 거의 동시에 이루어진다는 특징
기존의 하둡 시스템과 달리 ES cluster가 실행되는 동안에는 꾸준히 데이터가 입력(indexing)
그와 동시에 1초후 바로 검색 및 집계가 가능
4. RestFul API
표준 인터페이스(REST API)를 기본으로 지원,
Data에 대한 http Method를 통해 CRUD를 수행
5. Cluster 구성
대용량의 데이터 증가에 따른 Scale-Out & 데이터 Integrity(무결성) 유지를 하기 위한 구성
한 클러스터 내부에 하나 이상의 노드가 존재
- cluster : 여러 대의 컴퓨터 혹은 구성 요소들을 논리적으로 결합하여 하나의 컴퓨터처럼 사용할 수 있도록 하는 기술
- 여러 노드를 한 클러스터 내에 생성 - 부하 분산
- 여러 노드 중 한 노드 장애 발생 시, 다른 노드들로 클러스터 재구성 - 안전성 확보
- 여러 노드에 Data Replica(복제본) 생성 - 안전성 확보
→ 운영 및 확장성 용이
앞서 소개해드린 특징들을 통한 elasticsearch의 장점을 정리하자면 다음과 같습니다.

2. Logstash
두번째로 소개해드릴 구성요소는 Logstash 입니다

다양한 source에서 동시에 데이터를 수집 및 가공 , 전달하는 역할을 수행합니다
- 파이프라인으로서의 역할이며, 데이터를 수집하여 filter를 통하여 데이터를 변환(가공) 후, ES 혹은 다른 데이터 저장소로 데이터를 전달합니다.
- 다양한 Plug-in이 지원
- 확장 및 실시간 데이터 파이프라인 구축에 유용
Logstash의 데이터 처리를 위한 과정
1. Input
- Elastic의 logstash 는 입력 데이터의 다양한 형태와 크기, source등을 지원합니다.
2. Filter
- 데이터의 구문을 분석 및 변환 작업을 수행하며, 데이터의 형식이나 복잡성에 관계 없이 동적으로 변환합니다.
ex) grok filter - 비정형 데이터 구조 도출 / ip 주소 위치 좌표 해석을 하는 필터도 존재합니다.
3. Output
- ES를 포함한 다양한 데이터 저장소로 사용자의 요청에 알맞는 출력 형태로 전달합니다.
3. Kibana

ELK의 K를 맡는 Kibana입니다.
Kibana는 ElasticSearch의 데이터를 가장 쉽게 시각화할 수 있는 확장형 UI 도구입니다.
이를 통하여 사용자는
- - 검색 및 집계 기능을 통하여 손쉽게 ES의 데이터 조작 가능
- - 시각화 도구를 이용하여 DashBoard 및 Canvas 생성 가능
- 다양한 형태(json, url)로 저장 및 Export 가능
4. Beats
Logstash 는 데이터 수집기로 훌륭하지만,너무 많은 기능을 제공하기 때문에 상황에 따라 너무 무겁다고 판단할 수 있습니다
따라서 Elastic은 가볍게 데이터만 수집하는 Beats를 만들게 됩니다.

Beat는 지정된 위치의 Log file 만 읽고, logstash 혹은 ES로 전달해주는 역할만 수행합니다.
따라서 가공(필터)에 대한 역할을 잘 수행하지 않는 녀석입니다.(가공을 할 수 있긴 합니다)
Logstash vs Beats

Logstash
- 풍부한 기능을 제공합니다(filter 및 변환)
- Data 가공이 필요한 경우에 사용
Beats
- resource(CPU & RAM) 적게 소모
- Elasticsearch로 직접 전달할 경우에 유용
- 별도의 분석이 필요 없는 경우
- Log 자체가 json 형식이고, 가공할 필요가 없을 경우
위에서 설명한 beats는 logstash 혹은 elasticsearch로 log를 전달한다고 언급드렸습니다.

1번의 경우
Beat는 log 파일을 읽기만 하고 별도의 가공 X
로그 파일의 format이 달라진다면?
- parsing의 역할을 하는 Logstash의 설정을 변경해주면 됩니다.
따라서 이러한 경우는 beat 와 logstash의 역할을 분명히 나누었다고 볼 수 있습니다.
확장성 / 효율성 면에서 더욱 좋습니다.
2번의 경우
beat에서 json 형태의 문서로 가공
장점 : 빠르게 ES로 로그 전송 및 수집 가능
단점 : log file format이 변경되었을 때, 모든 application 서버의 beat의 설정을 변경해야함
Beat의 종류
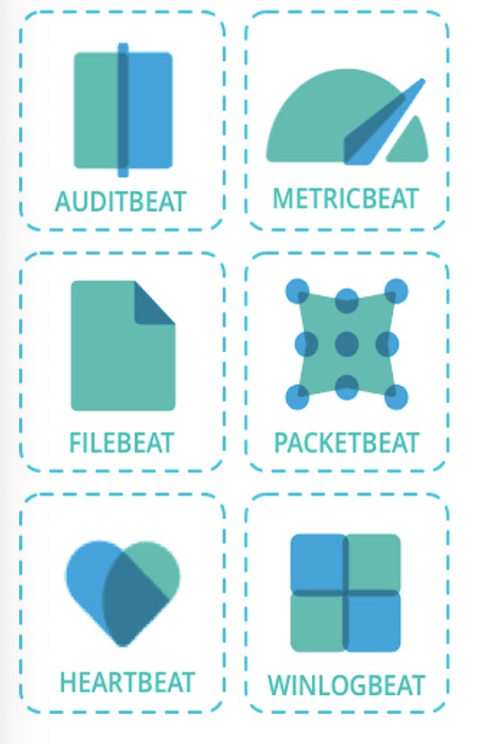
beat의 종류는 다양합니다. 간단하게만 정리해보았습니다.
- FileBeat : 서버에서 log file을 제공할 때 사용
- PacketBeat : 응용 프로그램 서버간에 교환되는 트랜잭션 정보를 제공하는 네트워크 패킷 분석기 역할
- MetricBeat : 서버에 실행중인 OS 및 서비스에서 메트릭을 주기적으로 수집하는 모니터링 에이전트
- WinlogBeat : windows 이벤트 로그 제공
- Heartbeat : 가동 시간 모니터링을 위한 경량 데이터 수집기로 활성 상태를 감지
- AuditBeat : Linux 시스템을 감사하는 프레임워크 데이터 수집기
X- Pack

Elastic Stack에 대하여 여러가지 확장 기능을 제공
Security - 인증기능, 사용자 관리, 노드, http elasticsearch 클라이언트 간의 통신 트래픽 보호등을 하며,
field / document 수준까지 데이터를 보호 / Audit Log(감시로그) 제공
Altering - 데이터 변경사항이 있다면, 사용자에게 알림 제공
Monitoring - ELK Stack 의 상태를 지속적으로 체크하는 기능
Reporting - PDF 형식의 주기적인 보고서를 생성할 수 있습니다. 또한 email에도 전송이 가능
Graph - 데이터 시각화를 그래프로써 표현
Machine Learning - 데이터의 흐름 및 주시성 등을 자동으로 실시간 모니터링하여 문제를 식별하고 이상값 탐지등 근본원인을 분석
Elastic Cloud

Elastic Stack을 AWS, Azure, GCP 등 원하는 가상환경에 맞추어 지원하는 Elastic의 SaaS입니다.
참고 자료 출처 :
- - https://esbook.kimjmin.net
- - https://17billion.github.io/elastic/2017/06/30/elastic_stack_overview.html
- - https://sabarada.tistory.com/46
- - https://victorydntmd.tistory.com/308
- - https://m.blog.naver.com/whdgml1996/222082868722
- - 기초부터 다지는 ElasticSearch 운영 노하우 – 박상헌, 강진우 지음
Elastic engineer로서 인턴을 시작하게 되면서 공부한 내용을 다시 정리하고 기록하기 위해 블로그를 작성해보았습니다.
현재 쓴 글은 많이 부족하고 분명히 틀린 부분도 존재할 것이지만, 나중에 좀 더 성장하게되면 수정하도록 하겠습니다.
만약 보시는 분이 있다면 참고용으로만 사용하시기를 권장드리며, 틀린 부분을 발견하신다면 댓글로 지적해주시는 것은 언제나 환영입니다